What is Synthetic Data Generation?
AI projects require enormous datasets with precisely marked certifiable information. Ordinarily, the bigger and more different the dataset, the better the model exhibition will be. Notwithstanding, it very well may be troublesome and tedious to gather the necessary volume of information tests and name them accurately. A developing option in contrast to genuine world datasets is synthetic data.
Rather than gathering and marking enormous datasets, there are a few procedures for creating engineered information that has comparative properties to truthful information. Synthetic data enjoys significant benefits, including diminished cost, higher exactness in information naming (on the grounds that the marks in engineered information are now known), adaptability (it is not difficult to make immense measures of mimicked information), and assortment. Engineered information can be utilized to make information tests for edge cases that don’t regularly happen in reality.
You can make synthetic data for a dataset — from even basic information to complex unstructured details like pictures and video. We’ll examine a few methods for creating engineered information, with an exceptional spotlight on the test of producing synthetic images for PC vision projects.
Techniques for Generating Synthetic Data
Generating Data According to a Known Distribution
You can make a synthetic dataset without beginning from genuine information for straightforward plain information. The cycle begins from a decent earlier comprehension of the dispersion of the genuine dataset and the particular qualities of the necessary information. The better comprehension you might interpret the information structure, the more reasonable the synthetic data will be.
Fitting Real Data to a Distribution
For straightforward plain information where a genuine dataset is accessible, you can make engineered information by deciding a best-fit conveyance for the accessible dataset. Then, in view of the appropriation boundaries, it is feasible to produce synthetic data of interest (as portrayed in the past segment).
You can gauge best-fit dissemination by:
- The Monte Carlo strategy utilizes rehashed irregular testing and measurable investigation of the outcomes. It very well may be utilized to make a minor departure from an underlying dataset that is adequately irregular to be practical. The Monte Carlo technique utilizes a straightforward numerical design and is computationally reasonable. Nonetheless, it is viewed as incorrect contrasted with other synthetic data generation techniques.
Neural Network Techniques
Brain networks are a further developed technique for producing synthetic data. They can deal with much more extravagant dissemination of information than customary calculations, for example, choice trees, and integrate unstructured information like pictures and video.
The following are three brain procedures usually used to produce engineered information:
- Variational Auto-Encoder (VAE) — an unaided calculation that can become familiar with the dissemination of a unique dataset and create synthetic data by means of twofold change, known as encoded-decoded engineering. The model forms a reproduction mistake, which can be limited with iterative preparation.
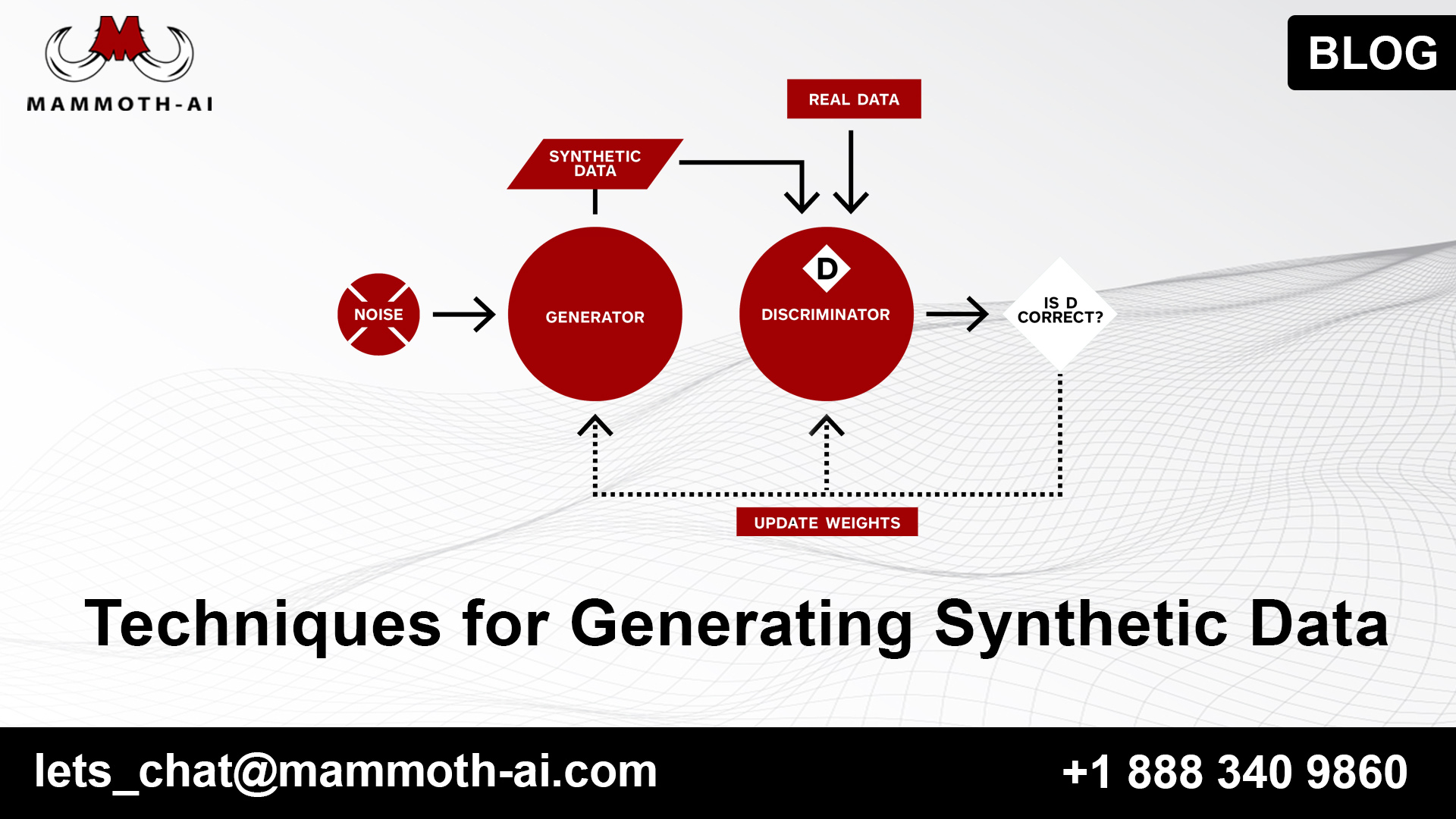
- Generative Adversarial Network (GAN) — a calculation in light of two brain organizations, cooperating to produce counterfeit yet practical data of interest. One brain network endeavors to create counterfeit data of interest while the other figures out how to separate phony and genuine examples. GAN models are mind-boggling to prepare and computationally serious, however, can create exceptionally definite, reasonable synthetic data points.
- Diffusion Models — calculations that bad preparation information by adding Gaussian commotion until the picture becomes unadulterated clamor, then, at that point, train a brain organization to invert this cycle, bit by bit denoising until another picture is delivered. Diffusion models have high preparation security and can create great outcomes for both picture and sound.
Verdict
Most synthetic data generation strategies are static, and that implies information researchers need to consistently change and recover them for new preparation goals, dispersions, or boundaries. Synthetic visual data, specifically, can be escalated to adjust. The standard strategies commonly center around a solitary undertaking or situation and don’t uphold continuous, responsive AI.