AI projects require enormous datasets with precisely marked genuine information. Normally, the bigger and more different the dataset, the better the model exhibition will be. Nonetheless, it very well may be troublesome and tedious to gather the expected volume of information tests and name them accurately. A developing option in contrast to genuine world datasets is synthetic data.
Process for Generating Synthetic Data
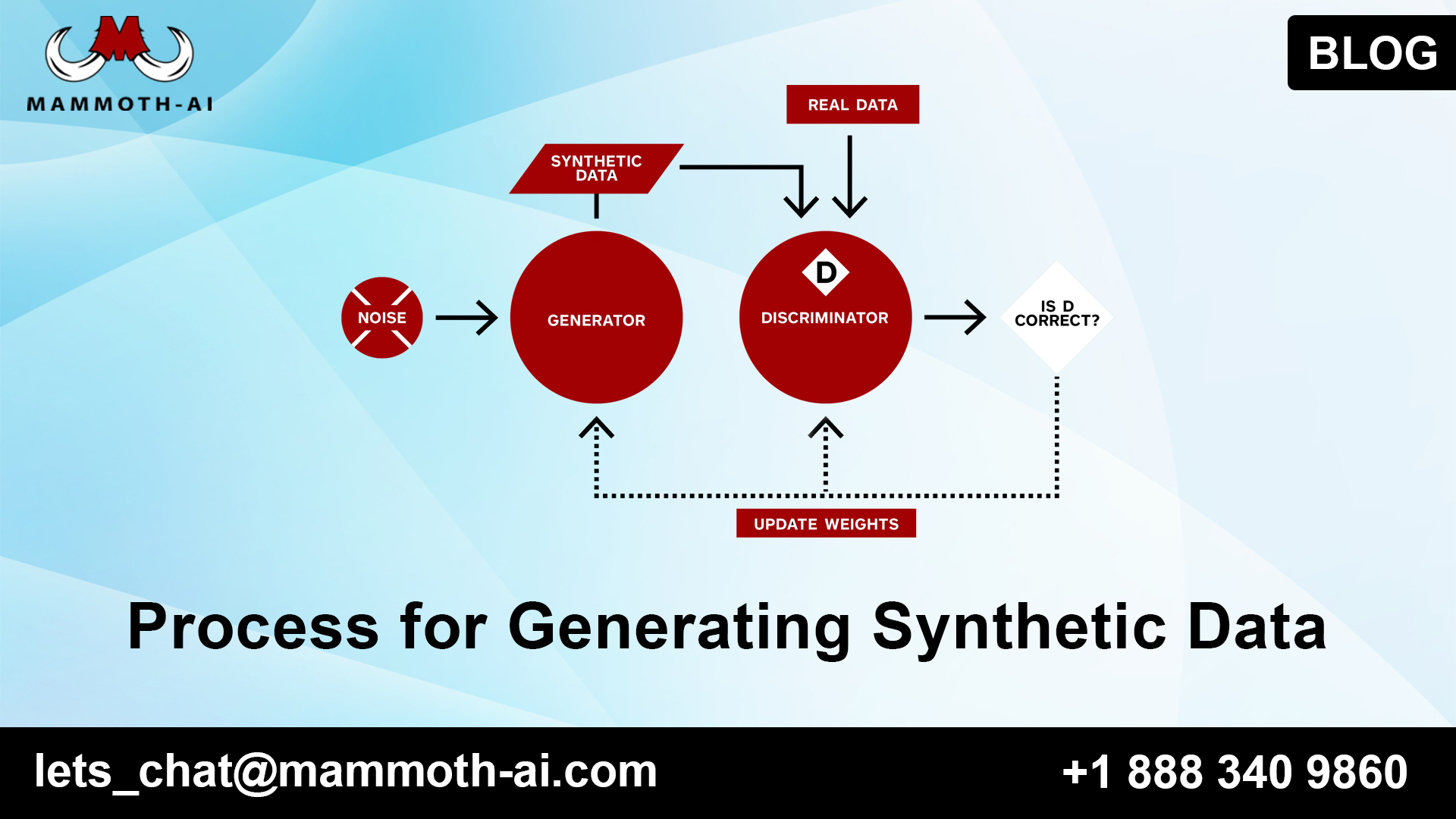
A developing option in contrast to genuine world datasets is the syntax you might want to produce engineered information for an AI project, here are the general advances you ought to adopt to decide your strategy:
- Decide business and consistence prerequisites — the initial step is to comprehend the targets of the manufactured dataset and for which AI processes it will be utilized. Moreover, comprehend on the off chance that imperatives like hierarchical approaches or consistency guidelines, precisely security necessities, influence your undertaking.
- Figure out which model to utilize — in the accompanying segment, we present a couple of choices, including Monte Carlo reproduction, VAE, and GAN. The model you pick will decide the specialized skill required and the computational assets as are necessary for the undertaking.
- Construct the underlying dataset — most engineered information procedures require genuine information tests. Cautiously gather the examples expected by your information age model, on the grounds that their quality will decide the nature of your manufactured information.
- Fabricate and prepare the model — develop the model design, indicate hyperparameters, and train it utilizing the example information you gathered.
- Assess synthetic data — test the manufactured information made by your model to guarantee it very well may be helpful for your situation. The best test is to take care of engineered information in your creation AI model and assess its presentation on real information tests. Utilize this input to tune your manufactured dataset to all the more likely suit the necessities of the ML model. hectic information.
Some Challenges of Synthetic Data Generation?
While there are many advantages to engineered information, it presents a few difficulties:
- Data quality— quality is a vital worry for preparing information and is particularly significant for synthetic data. Excellent synthetic data catches similar essential design and factual dissemination as the information on which it is based. Notwithstanding, by and large, engineered information contrasts with genuine information in manners that can influence model execution.
- Keep away from homogenization — variety is basic to fruitful model preparation. On the off chance that the preparation information is homogenous, zeroing in on unambiguous sorts of data of interest and neglecting to cover others, the model will have lackluster showing for those different information types. Genuine information is profoundly different, and producing engineered information that catches the full scope of diversity is fundamental.
Synthetic Data Generation Best Practices
Work with Clean Initial Data
Clean information is a significant prerequisite for synthetic data creation. Remember the accompanying standards while setting up a synthetic dataset:
- Clean the underlying information utilized by the synthetic data generator. Right, and eliminate off-base records (known as “grimy” information). Starting datasets should be predictable and liberated from mistakes that could bring about unusable synthetic data. Nonetheless, take care not to eliminate exceptions or significant highlights that show up in the reality dataset.
- Reconcile the data to guarantee that all contributions to the manufactured information generator are uniform and predictable. If the information is plain, all document designs should be changed over completely to one configuration, and all tables should have a uniform diagram. If the information is unstructured, all information tests ought to utilize a similar document design, visual size, goal, and quality. Remember that unobtrusive varieties in your example information can present bigger varieties in the synthetic data, which will hurt model execution.
Assess and Improve the Synthetic Data
It is vital to assess manufactured information prior to utilizing it to prepare a creation model. There are multiple ways of assessing information:
- Manual investigation — an information investigator acquainted with true information can examine an example of records and check whether they seem reasonable. Human evaluators can give significant subjective criticism — to model, they can check if the dataset is adequately different and give remarks about unambiguous information focuses that may be deceiving for the model.
- Statistical analysis — layout measurements for model variety and likeness to the conveyance of a similar genuine dataset. Assess occasion successions, highlight dispersions, connections amongst elements, and substance connections. Figure the measurements and guarantee that the dataset meets the necessary rules.
- Training runs — train the model in a non-creation climate utilizing the engineered dataset and afterward assess its exhibition on known or human-named data of interest. This is a definitive trial of engineered information — might it train a model to accurately handle certifiable information at any point?
- In view of the above criticism, finetune and further develop your engineered dataset. Making a successfully synthetic dataset is an iterative interaction that requires a few rounds of experimentation.
Think about Consistence Prerequisites
On the off chance that the information relates in any capacity to living people, it is possibly covered by consistency guidelines like GDPR, CCPA, or HIPAA. Address consistency groups in the association and comprehend the consistence prerequisites and limitations for the manufactured information project. Guarantee that the subsequent synthetic dataset doesn’t make a security risk. Remember that your underlying information, which could contain delicate details about living people, should be safeguarded and treated with care.
Verdict
Most synthetic data generation techniques are static, which means data scientists have to regularly adjust and regenerate them for new training objectives, distributions, or parameters.